Getting my data out of Strava onto my own computer
Posted: Fri 22 May 2026Filed under personal
Tags: personal programming
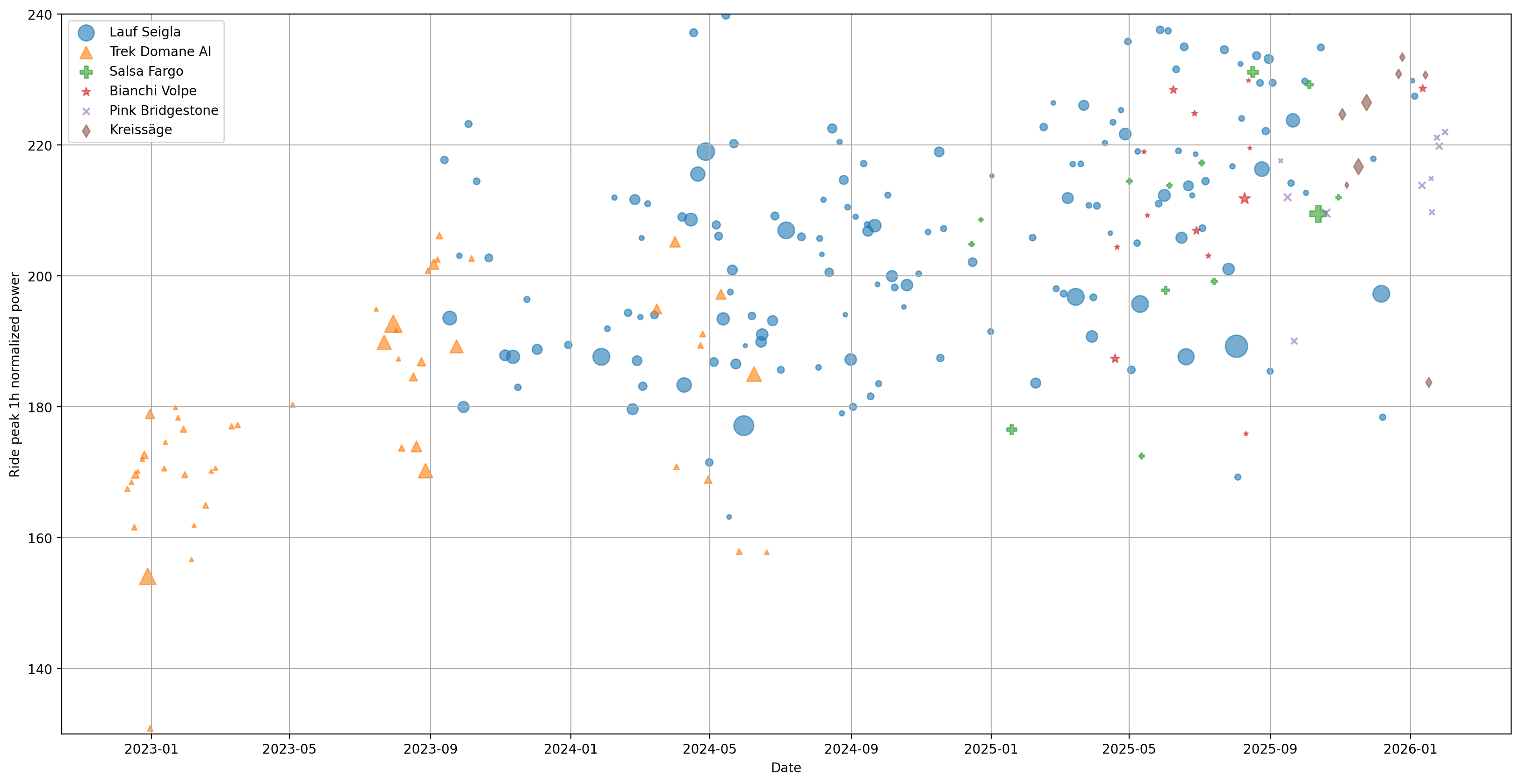
I have been using Strava pretty consistently over the last 6 years to track my runs, and from December 2021 onwards, my rides as well. At some point in that interval, the runs got less frequent, while the rides got more frequent, and along with that, I started collecting more data on my rides: first heart rate, then cadence, and finally in the summer of 2023, power meter data. Since then I've used my power data to pace long rides, and monitor performance improvements (or lack thereof) over time.
Eventually, I realized I was asking questions of my data that the Strava UI was not good enough to effectively handle, for example:
- How has my peak 1 hour normalized power changed over time? What if I want to filter out rides shorter than 2 hours before answering this question?
- Do I put out more power on my somewhat aggressive road/gravel bikes than on my relaxed drop bar mountain bike or commuter bike?
At the same time, I started hearing news about the impending Strava IPO, and worried it would lead to eventual enshittification, along with all of my upload data.
To deal with both the issue of trying to answer more granular questions, and getting my data out of Strava and onto my own computer, I decided to build strava-history-analysis, which is effectively a data downloader and updater for my Strava activities, combined with some data science tools to run the kind of queries I was imagining. This was also an excuse for me to play around with three pieces of software I had been meaning to dabble in (at the time, which was late December 2025 or early January 2026).
- Polars: This dataframe library had some clever lazy streaming APIs to deal with datasets larger than one could store in memory. That never really factored into this project, since the datasets were relatively small, but it was still useful to work with a better dataframe API than pandas (or the internal library from work).
- Marimo: This Python notebook UI has some benefits over Jupyter, namely that the source code of a notebook is pure Python, and that the cells of the notebook are nodes in a directed acyclic graph, which rules out the strange irreproducible bugs in Jupyter notebooks where some hidden state affects the execution output.
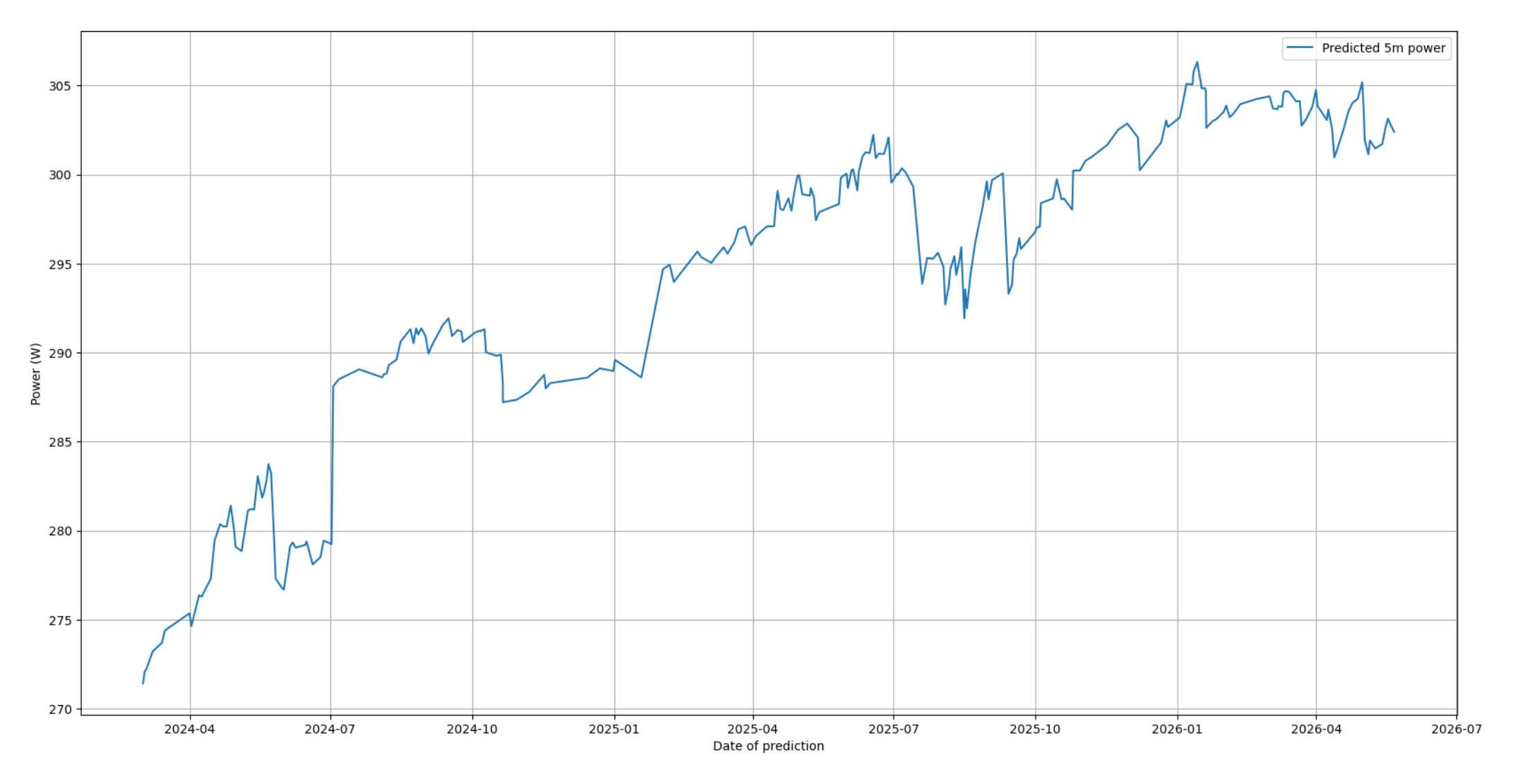
- Claude: I don't really need to explain what this is, since that has just become a part of the zeitgeist since late 2025, but I went into this project being a relative AI skeptic, and came out a very cautious optimist. In particular I was able to use Claude to do some of the more mundane parts of the project with minimal prodding, except for some stylistic decisions. I managed to get Claude to build a general caching mechanism for the activities in my dataset so that I wasn't computing the secondary time-series features from scratch, as well as build a hyperparameter search script to determine the best hyperparameters for the pacing model. Both of these tasks were relatively easy, and I had concrete ideas on how to do them, and I knew I could easily validate the output of Claude if provided the code.
Claude was also pretty useful in helping me pick the project back up a few times if I went a few weekends without working on it, which is part of the reason why I feel like I've finished the project now. I continue to use the analysis library to analyze my fitness trends, especially for the metrics that interval.icu does not provide me, and I've used the pacing calculator to great success for my 300k and 400k this season.